Written by Peter Joffe
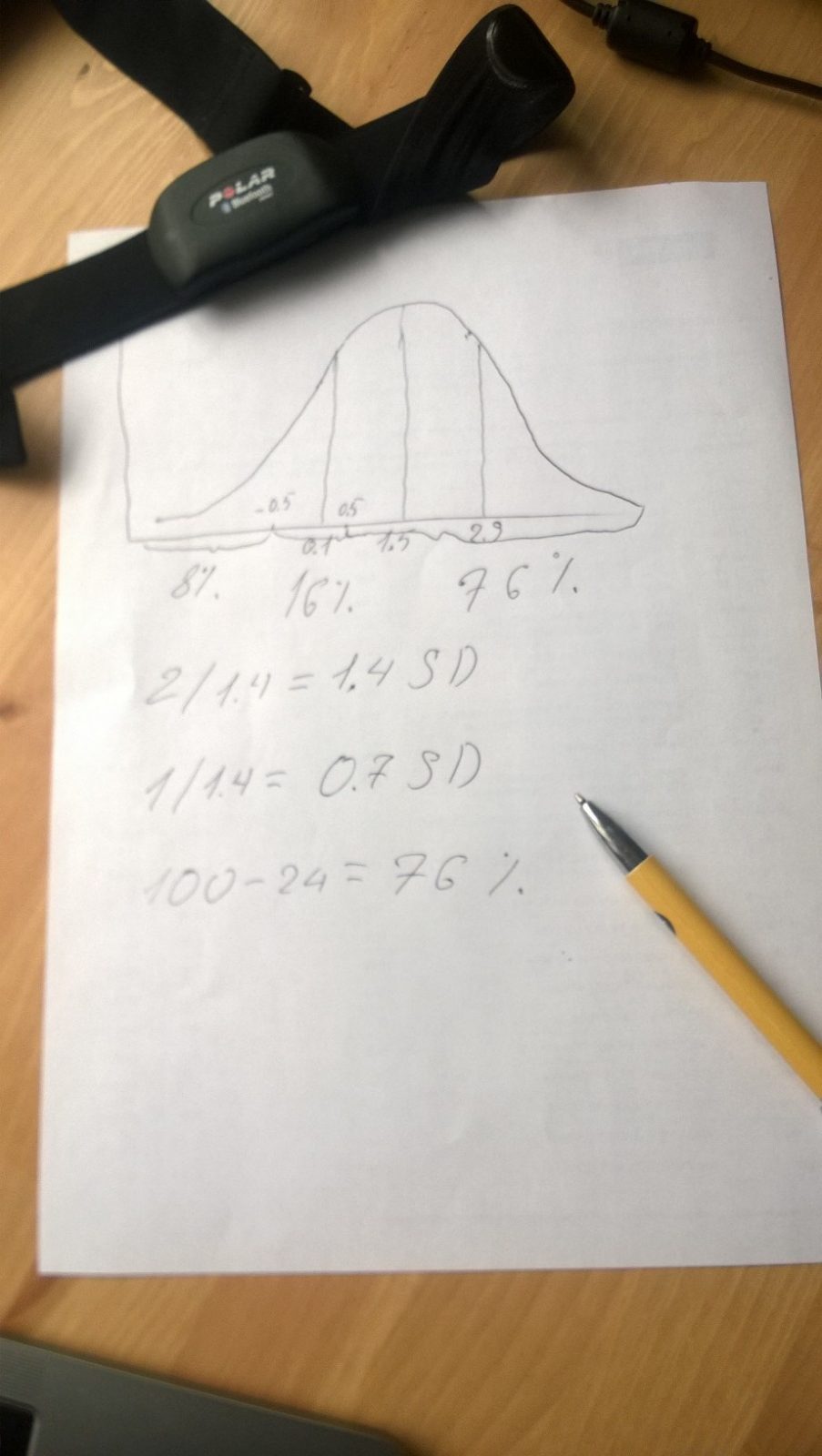
Popular Science journals and the general public as well, don’t like negative results. Although such results may be valuable for science, people prefer ideas which promise fast and tremendous success. “Drink beetroot juice, and you run faster and longer!”, “Do our special TRX programme, and you gain incredible core strength! “Follow this diet and..!” Very often such advertisement followed by another cliché – “Scientific studies proved this.”
However, how, actually, scientific research proves something? Well, it uses a powerful weapon — Statistics.
Statistics is indeed a handy tool for science. Maybe because Nature itself is based on probability, Statistics, whose “…inferences are made under the framework of probability theory” (Wikipedia), is a robust method to describe natural events. However, when using inappropriately, Statistics may support wrong notions and create confusion.
Is statistical significance always significant?
Most of us who studied Sports Science at universities were taught to use statistical significance. In most studies and experiments, scientists explore the probability that their intervention makes a difference. However, they always have to admit that this difference may happen by chance. So, before the experiment, they have to set the acceptable level of probability that a positive result happens accidentally – a. Then they do a research and obtain study’s probability of by-chance positive result — P. This value of P must be below the pre-determined level for acceptance of study as “statistically significant.” Otherwise, an idea should be rejected.
However, you can use some manipulations for changing P-value. For example, it significantly depends on sample size (how many participants you have tested). Martin Buchheit showed how the inclusion of just two people into the group of twelve changed research conclusion on the opposite, even though critical parameters, such as mean and standard deviation, remained the same. So, if you have twelve people then: “scientists proved that… the intervention had no effect”. However, include just two more participants and: “scientists found a significant effect of… on performance”.
A temptation for scientists, who are desperate to find something to publish is too big, and sometimes they cannot resist manipulating with significance. Then we have a published article which is cited by other authors and – vu-a-la ! Now we have “widely accepted scientific opinion” which should be followed by coaches and athletes.
Other disadvantages of P-value method are that it is not suitable for testing individual athlete and it does not show the magnitude of changes (though you can do it with additional analysis). Perhaps scientists are most interested in general tendencies, however, coaches more care about the extent of changes in an individual athlete. Did he/she improve? How sure may we be that he/she improved? Is this improvement big enough to influence performance? Until recently, I thought that the answers to these questions might be only based on coach’s experience. However, in works of Martin Buchheit and William Hopkins, I have found a statistical method which can give statistical support for our intuition.
It is Magnitude Based Inference (MBI). I would like to describe it in this post. It is necessary to note that many statisticians do not agree with the MBI and this method is widely criticised. Mainly this critique targeting application of MBI in scientific studies. I am not specialist in statistics, and I cannot participate in discussion.
Therefore this article does not aim to advise researchers on stats. To make conclusions about study scientists probably need more robust and strict statistics than it is needed for practitioners in the field. Therefore they should be careful in choosing appropriate statistical method and to seek expert opinion on that.
We, practitioners, perhaps are more free to form our opinion because we do not claim universal value of our training methods and do not need to prove something scientifically. Often this opinion is based on intuition, beliefs, and experience. Sometimes, however, some mathematical logic can be useful in assessing performance and in making decisions.
In that sense, application of Magnitude Based Inference for testing an individual seems plausible to me. I would like to share my understanding of its logic. I will try to keep the explanation as simple as possible; nevertheless, some math is unavoidable.
Some necessary stuff.
A few things we need to know before start:
Standard Deviation (SD) is a measure of variability of data. For example, you may have test results: 1;2;3;4;5;6;7;8;9;10 and 4;4;5;5;5;6;6;6;7;7. It is obvious that the first set of data is more dispersed than the second although their means are the same (5.5). This pattern may tell practitioner that first data set was from athletes with completely different abilities or the test itself is hugely unreliable. SDs values reflect this. For the first set, it is 3.03 whereas for the second 1.08. Mathematically, SD is a square root of variance (average of squared distances from the mean). Another useful property of SD is that it allows quantifying the distribution of chances for a particular range of values to occur. For example, values between -1SD and +1SD (3.6 and 8.4 on picture 1) have 68% probability to happen (for normal distribution). There are some good explanations of SD on Internet and, trust me, it is not too complicated.
Coefficient of variation ( CV) is a measure of relative variability: SD/Mean. Very often expressed as SD/Mean x 100%.

Picture 1. Normal distribution.
Are you sure about test results?
So, we tested an athlete and, at first glance, things look very simple. If his/her result is better than it was in the previous test, we can conclude that the athlete improved. The first question from sceptics follows immediately: how sure we are in our conclusion? The result may be just a consequence of the natural variations in athlete performance and test conditions. That is, so-called, Error of Measurement or Typical Error (TE).
Keeping in mind TE problem, we need to address the second question: what is the smallest progress in the test that can give us a hope for an improvement in real competitions? This is the Smallest Worthwhile Change (SWC).
SWC.
Let’s start with the last question. List of SWCs for different physical tests already exists, thanks to work of mentioned above authors and other scientists. However, it is always good to understand in general the idea behind this guidance.
For solo events (track and field, bike, swimming, etc.), SWC may be derived from variations in performance. To that, you need to know CV for chosen event. You can find it by yourself analysing performance of your athlete in different competitions. For example, athlete showed results 10.1; 10.1; 9.9; 10.0; 10.1; 9.9; 9.9 seconds in 100 meters sprint during seven events. His average time is 10.0 sec and SD of data is 0.1 sec. That gives us CV of 0.1/10=0.01 or 1%.
Alternatively, we may take a typical CV value for the similar population of athletes.
Using observation and simulations, William Hopkins already did some work for us. He made a list of CVs for different events and suggested SWC as 0.3 CV. Thus, for our example, improvement of 0.03 sec (0.3% of mean) is SWC.
Changes of 0.3; 0.9; and 1.6 of CV Hopkins suggested considering as small, medium and large respectively.
A situation may be a little bit more complicated in team sports where there is no apparent connection between test and performance. For them, a suggestion is to use team data and calculate SWC based on Cohen d coefficient. You need to find a difference between player result in the first and second tests and divide it by an overall team (between-subject) SD in these tests. So we compare changes for an individual player against all team variation. Improvements equal to 0.2 is SWC, whereas larger than 0.5 and 0.8 are medium and large change respectively.
Alternatively, SWC can be defined based on common sense and experience. For example, Martin Buchheit suggested considering 1% improvement in 20 m sprint test meaningful for a footballer, because 20 cm is a minimum distance player needs to be ahead of opponent for winning the ball.
So, don’t be afraid to set your own, logically grounded SWC.
There are a few important things however.
First, you should define SWC before the test. It will be no good to conduct the test first and then start playing with SWC trying to find positive result.
Secondly, SWC in your test is connected with its TE.
If you make SWC too small it may look like a good thing because you will not rejecting the small changes in performance. However this SWC may be really small compare to test noise—TE, so you cannot be sure if such changes are real.
On the other hand, big SWC although is good for SWC/TE ratio, nevertheless may be too strict and rejects small but important improvements. So, there is some kind of trade-off here.
Well, now we define SWC; nevertheless, it is still not enough information to say how sure we are that the test showed changes. We need to deal with TE of the test. First of all, we have to find it.
Typical error.
When testing an athlete, we are interested in finding his/her “true result” in this test. Theoretically it can be done by testing an athlete infinitely many times and computing average of these tests. It is obvious that such design is unreal and in reality our measurements are not precise . Thus it is necessary to take into account a random, unavoidable and unpredictable error of measurement in the test which is always present. It is why it is called “typical”.
Because TE is a measure of reliability of a chosen test, we have to have a clear understanding about the amplitude of TE in our test for making a reasonable conclusions how close to “true result” may be to our data.
TE of the test is a “noise” which spoils the signal (real result); thus it is always better if the noise would be less than SWC. We can reduce noise by testing an athlete repeatedly over the short period and take the average of these tests. In this case variances responsible for TE tend to cancel each other. TE of test is reduced by a factor √N (N=number of measures). For example, the average of two tests reduced TE by 30% whereas four tests halves TE.
You can find TE for some tests in literature but sometimes it may be useful to know how to calculate it.
Example:
We want to find out how reliable is golf-putting test. It means that we are interested to find test TE. Our participants are not golf players, so their technique and experience are equal. We give to five subjects for ten strokes each, and they try to score as many as possible.
We have two ways to measure the reliability of the test. First is to give one person a few tests, let’s say 8-10, and look how his results vary between these tests. SD of her results is TE. It means that test results vary due to random variations in athlete performance and test conditions.
However, this may be not exactly true because variations can happen due to participant learns the test and rapidly improve at the beginning. It is always better to give relatively simple and already well learned test. However, even then, to perform 8-10 tests over short period may be impractical.
Thus Hopkins suggested another way: to test group of subjects two times and to find changes between the tests for every person. After that we need to analyse how dispersed are these changes—to compute SD of changes.
As I understand, Hopkins assumed that SD of changes over short period is relatively independent of learning and participant’s abilities. Most part of the variability of changes between participants then happens due to variability of the test itself—TE.
So let’s see how our participants performed (picture2).

Picture 2. Tests results in golf-putting task.
We can see that results vary between subjects and between two test for most participants (except Polly).
Variations between subjects combine TE of the test and difference in their abilities and we need to separate these two factors.
As was discussed above, SD of changes may eliminate this problem. So we have:
Mean (of changes) =0
SD (of changes)= 2.24
We already see that changes are quite spread out.
Now we can calculate TE:
TE=SD/√2
Why we divided SD changes by √2? It follows from the assumption that variances which are responsible for TE of each test transfer into test’s differences and combined.
Therefore, variance of the differences is equal to the sum of TE-variances of two tests.
Because SD is a square root of variance now we may write following:
Squared SD of differences (SDD) is a sum of squared SD which is responsible for TE of each test (SDTE).
SD2D=SD2TE+SD2TE → SD2D=2SD2TE → SD2TE=SD2D/2 → SDTE= SDD/√2.
This means that part of the test SD which is responsible for TE is equal to SD of individual changes between two tests divided by 1.4. This conclusion will be useful for us in the future.
TE of test= SD (of changes between test-retest) /1.4
In our example: 2.24/1.4=1.6
So, TE in this test, for these population of subjects is 1.6 shots.
From a practical point of view this means that improvement after training of 1-2 good strokes from 10 cannot be considered as reliable. Or, to say it differently: if a difference between two participants after ten attempts is just 1-2 good strokes, we may not be sure that they definitely have different abilities in putting.
Test analysis.
So now we have all necessary ingredients for analysing the results of testing an individual athlete statistically. These ingredients are TE of the chosen test, SWC and observed change. The final piece of math allows us to find out the probability that the test result reflects improvement, trivial changes, or even impairment.
Let’s take an example:
We test a player before pre-season camp and after that and found that he/she improved by 1.5%. We know from the literature or we estimated that SWC for this test is 0.5% and TE is 1%.
Despite the fact that observed change (OC) shows improvement, and it is higher than TE of the test (which is good), the probability of trivial changes (no changes) and even impairment still exists.
The probability that “true change” lies between 0 ± SWC (-0.5 and 0.5 % in this case) is the probability of trivial change.
Below -0.5% — harmful change.
Over 0.5% — beneficial change.
So, how exactly probability is distributed in this example?
First, we assume that probability has a normal distribution (bell shape curve and even distribution of chances astride OC.
Next, we need to transfer TE back to SD because we need SD for calculations of chances:
1% x √2 =1%×1.4. SD of changes for this test is =1.4%.
What does that mean? It means that chances to find “true change” with this test are distributed around OC with SD of 1.4% change.
From now on, I am going to use the word “unit” instead of “percent” when I talk about changes. This will be better to avoid confusion between percent of changes and percent of probability of this change to occur; thus 1 unit of change=1% change.

Picture 3. Distribution of probability for changes.
Then we can use Z table which shows a distribution of chances for “true result” to occur somewhere within our normal distribution. These chances are distributed relative to the distance (expressed as a fraction of SD) from the mean (in this case OC). Further from OC – fewer chances that true test result is there. Now have a look at the picture 3.
Point -0.5 is 2 units below from point 1.5 (OC) That is a distance of 1.4 SD (2/1.4=1.4)
In accordance to Z-table, beyond a point -1.4 SD chances to meet “true value” are 8 %. So, 8% is the probability that our athlete, actually, decreased his performance.
Point 0.5 is 1 unit below from 1.5 That is 0.7 SD (1/1.4=0.7)
Below -0.7 SD are 24 % of chances. Thus between -0.5 and 0.5 are 24-8= 16 % chances of trivial changes.
All changes that are above 0.5 are chances for improvement. This gives us: 100-24=76%
Conclusion: We have 76% confidence that changes are beneficial and athlete improved.
There is another, more simple, way to report the results. Hopkins suggested using “Likely Limits” . This means that athlete “true result” most likely lies somewhere inside these limits. The borders of this range are defined as OC±TE. How is likely “true value” inside? Well, if TE is 0.7 SD (1/1.4) then inside OC±0.7 SD are 52% chances ( Z table).
If whole limit is inside, let’s say, “beneficial” area we can call result “clear beneficial”. However if limit spreads between two or three areas then it would be “unclear”.
In our example, limits are 1.5±1. The nearest low border is point 0.5 from where trivial changes begin. Our low limit is 1.5-1=0.5 which is precisely on the border of trivial changes. So we can conclude that likely limits in this test are entirely inside the beneficial area, and the result is “clearly beneficial” (picture 4).
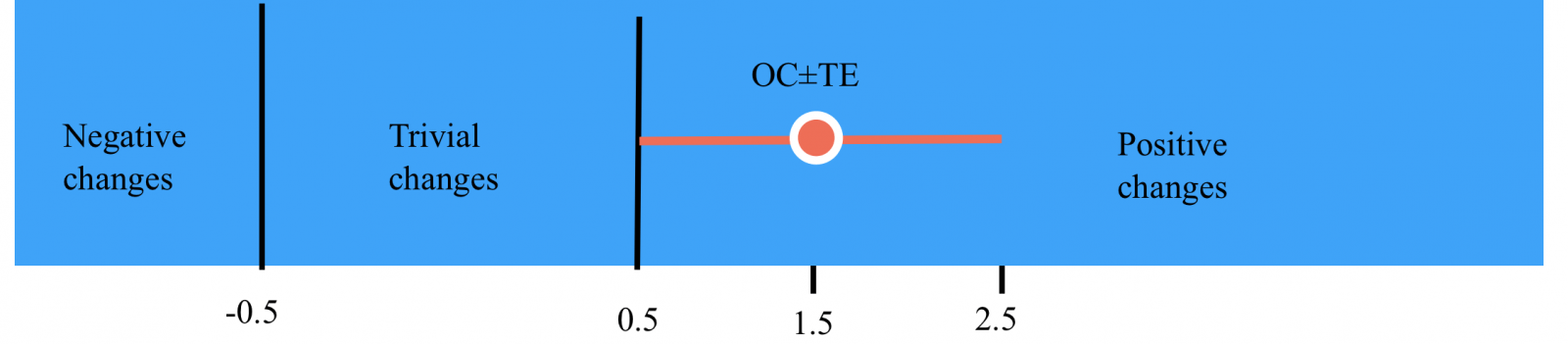
Picture 4. Likely Limits.
We can see that outside Likely Limits (LL) remain 48% of chances to find true change. Half of them is above limits and half below. If we add upper half (24%) to our LL we will get the same 76 % chances for positive change that I have calculated before. However, this is so easy just because, in this case, LL starts exactly from the border of trivial changes.
Conclusion.
Despite all this looks a little bit complicated, there is nothing that may prevent thoughtful readers, whether they are athletes, coaches and, especially, applied sports scientists, to understand the idea. Math is at the level of squares and square roots, and stats is at the basic level as well. For those, who don’t want or have no time to make calculations, there is Excel spreadsheet freely available. Recently, I also created simple online calculator for analysing individual athlete. However, it is always useful to understand the method, at least in general. Thus, I strongly advise doing so. In my opinion, this is the case when, Statistic instead of being something scaring and vague for practitioners, can provide a useful tool for a scientific approach to performance.
Literature.
1. Bartlett, J. W., and C. Frost. “Reliability, repeatability and reproducibility: analysis of measurement errors in continuous variables.” Ultrasound in obstetrics & gynecology 31.4 (2008): 466-475.
2. Batterham, A. M., & Hopkins, W. G. (2006). Making meaningful inferences about magnitudes. International Journal of Sports Physiology and Performance, 1(1), 50-57.
3. Buchheit, M. (2016). The Numbers Will Love You Back in Return-I Promise. Int J Sports Physiol Perform, 11(4), 551-554.
4. Errors of measurement, theory, and public policy. https://www.ets.org/Media/Research/pdf/PICANG12.pdf
5. Interpreting the result of fitness testing (Pyne, 2018).
6. Hopkins, W. G. (2000). Measures of reliability in sports medicine and science. Sports Medicine, 30(1), 1-15.
7. Magnitudes matter more than beetroot juice https://sportperfsci.com/magnitudes-matter-more-than-beetroot-juice/
8. Want to see my report coach? https://martin-buchheit.net/2017/02/18/want-to-see-my-report-coach/